SynthRank: Synthetic Data Generation of Individual’s Financial Transactions Through Learning to Ranking
Abstract
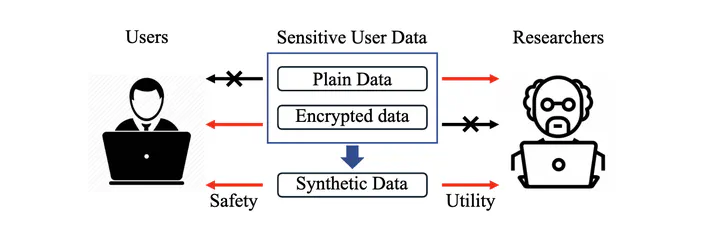
Synthetic data generation is being seen as a solution to the problem of acquiring data to build artificial intelligence models. In particular, obtaining financial transaction data is notably challenging, largely attributed to strict privacy regulations and the sensitivity of personal financial details. In contrast to existing approaches that utilise generative models dedicated to replicating authentic data distributions, this paper proposes SynthRank, a novel approach founded on the learning-to-rank (LETOR) algorithm, for financial transaction synthetic data creation. Focusing specifically on trading transactions, we address the risky trader detection and prediction challenge by leveraging LETOR techniques to generate ranking scores for each attribute of the transaction set. These scores are aggregated into a new vector, constituting the synthetic data. By segmenting data into distinct ranking groups, we produce synthetic data without quantity limitations. Our approach offers privacy protection of individual data, since sensitive information becomes challenging for attackers to infer. Our comprehensive analysis demonstrates that SynthRank not only enhances utility but also preserves the essential distribution characteristics of the original dataset while providing privacy protection.
Type
Publication
AI in Finance for Social Impact @ AAAI 2024