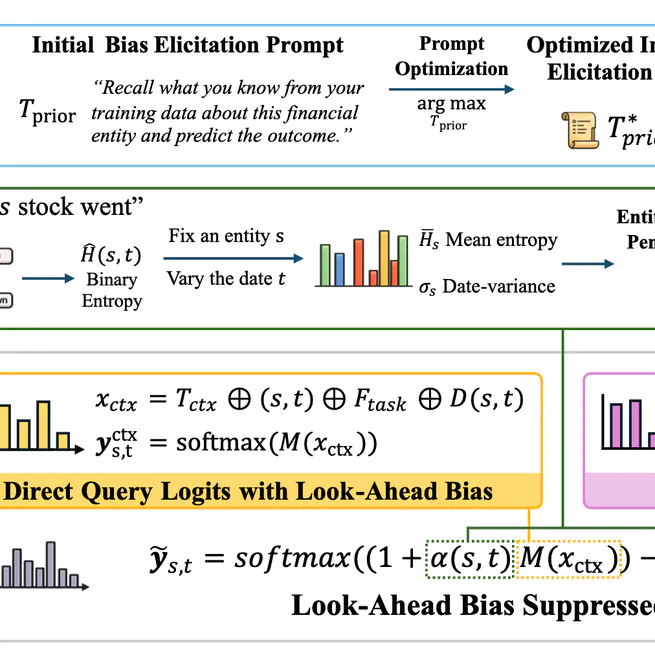
Summoning the Oracle to Slay It: Mitigating Look-Ahead Bias in Financial Backtesting with Large Language Models
Citation @misc{li2026summoningoracleslayit, title={Summoning the Oracle to Slay It: Mitigating Look-Ahead Bias in Financial Backtesting with Large Language Models}, author={Weixian Waylon Li and Mengyu Wang and Tiejun Ma}, year={2026}, eprint={2605.24564}, archivePrefix={arXiv}, primaryClass={cs.AI}, url={https://arxiv.org/abs/2605.24564}, }
May 26, 2026
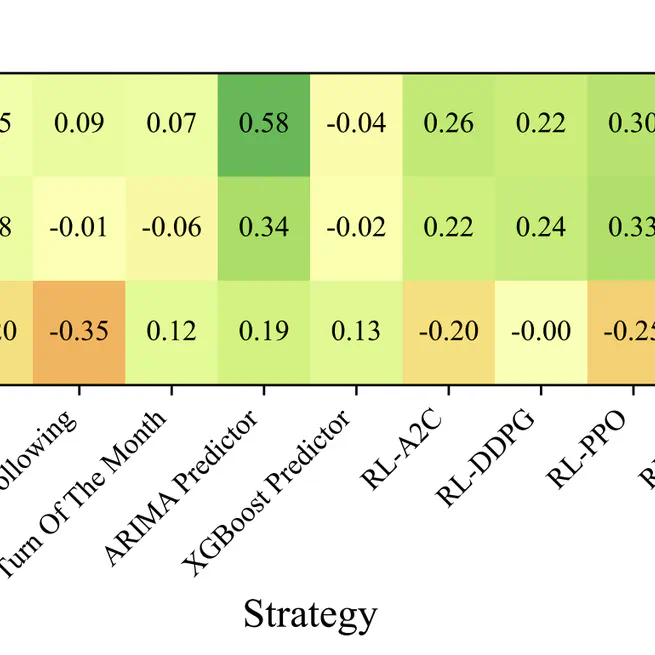
Can LLM-based Financial Investing Strategies Outperform the Market in Long Run?
Citation @inproceedings{10.1145/3770854.3785702, author = {Li, Weixian Waylon and Kim, Hyeonjun and Cucuringu, Mihai and Ma, Tiejun}, title = {Can LLM-based Financial Investing Strategies Outperform the Market in Long Run?}, year = {2026}, isbn = {9798400722585}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, url = {https://doi.org/10.1145/3770854.3785702}, doi = {10.1145/3770854.3785702}, abstract = {Large Language Models (LLMs) have recently been leveraged for asset pricing and stock trading applications, enabling AI agents to generate investment decisions from unstructured financial data. However, most evaluations of LLM timing-based investing strategies are conducted on narrow timeframes and limited stock universes, overstating effectiveness due to survivorship and data-snooping biases. We critically assess their generalizability and robustness by proposing FINSABER, a backtesting framework evaluating timing-based strategies across longer periods and a larger universe of symbols. Systematic backtests over two decades and 100+ symbols reveal that previously reported LLM advantages deteriorate significantly under broader cross-section and over a longer-term evaluation. Our market regime analysis further demonstrates that LLM strategies are overly conservative in bull markets, underperforming passive benchmarks, and overly aggressive in bear markets, incurring heavy losses. These findings highlight the need to develop LLM strategies that are able to prioritise trend detection and regime-aware risk controls over mere scaling of framework complexity.}, booktitle = {Proceedings of the 32nd ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.1}, pages = {2711–2722}, numpages = {12}, keywords = {automated trading, llm investors, backtest, benchmark}, location = {Republic of Korea}, series = {KDD '26} }
Nov 24, 2025
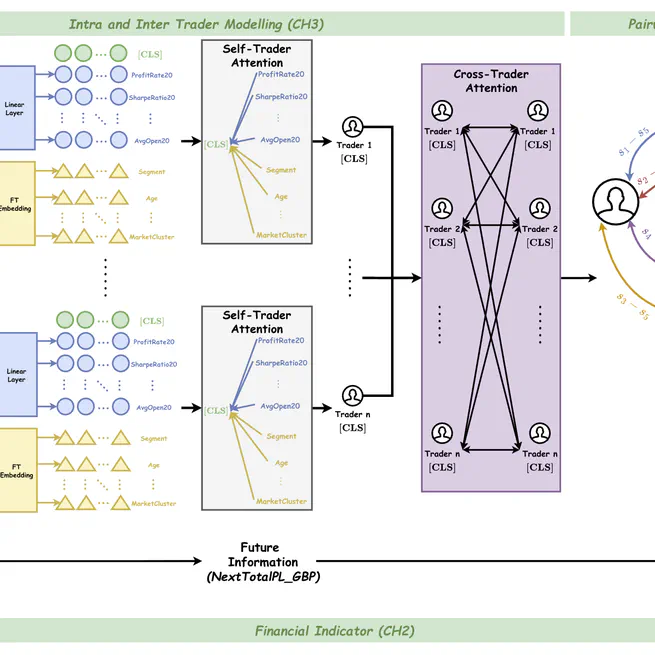
Learn to Rank Risky Investors: A Case Study of Predicting Retail Traders' Behaviour and Profitability
Citation @article{10.1145/3768623, author = {Li, Weixian Waylon and Ma, Tiejun}, title = {Learn to Rank Risky Investors: A Case Study of Predicting Retail Traders’ Behaviour and Profitability}, year = {2025}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, issn = {1046-8188}, url = {https://doi.org/10.1145/3768623}, doi = {10.1145/3768623}, abstract = {Identifying risky traders with high profits in financial markets is crucial for market makers, such as trading exchanges, to ensure effective risk management through real-time decisions on regulation compliance and hedging. However, capturing the complex and dynamic behaviours of individual traders poses significant challenges. Traditional classification and anomaly detection methods often establish a fixed risk boundary, failing to account for this complexity and dynamism. To tackle this issue, we propose a profit-aware risk ranker (PA-RiskRanker) that reframes the problem of identifying risky traders as a ranking task using Learning-to-Rank (LETOR) algorithms. Our approach features a Profit-Aware binary cross entropy (PA-BCE) loss function and a transformer-based ranker enhanced with a self-cross-trader attention pipeline. These components effectively integrate profit and loss (P&L) considerations into the training process while capturing intra- and inter-trader relationships. Our research critically examines the limitations of existing deep learning-based LETOR algorithms in trading risk management, which often overlook the importance of P&L in financial scenarios. By prioritising P&L, our method improves risky trader identification, achieving an 8.4\% increase in F1 score compared to state-of-the-art (SOTA) ranking models like Rankformer. Additionally, it demonstrates a 10\%-17\% increase in average profit compared to all benchmark models.}, note = {Just Accepted}, journal = {ACM Trans. Inf. Syst.}, month = sep, keywords = {learning to rank, domain-specific application, individual behaviour modelling, risk assessment} }
Sep 3, 2025
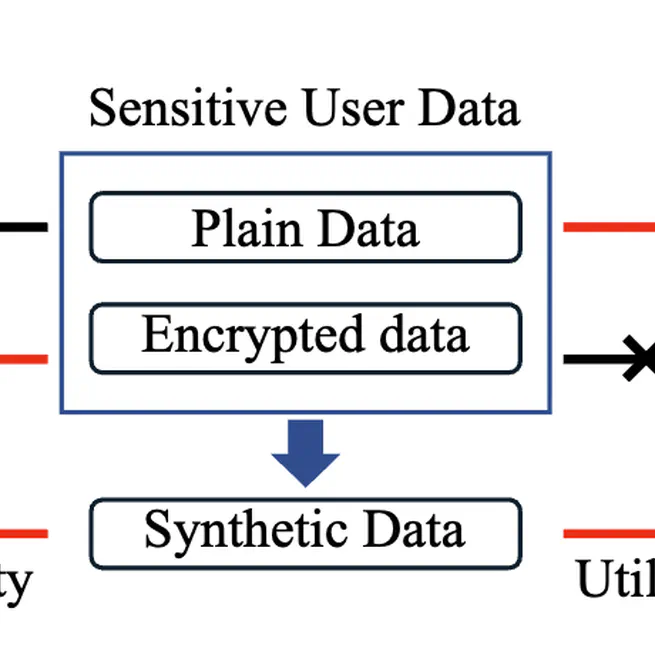
SynthRank: Synthetic Data Generation of Individual’s Financial Transactions Through Learning to Ranking
Feb 1, 2024