对比学习简介

(这篇博文用英文攥写并翻译自ChatGPT)
有关阅读材料:
- The Beginner’s Guide to Contrastive Learning
- SimCSE: Simple Contrastive Learning of Sentence Embeddings
- A Simple Framework for Contrastive Learning of Visual Representations
- Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
背景
对比学习旨在通过将语义上接近的邻居聚集在一起并将非邻居推开来学习有效的表示。最初,对比学习应用于计算机视觉任务。如下图所示,我们期望模型学习具有相同标签的两个图像之间的关联性,以及具有不同标签的图像对之间的差异。
这个想法与人类从经验中学习的方式非常相似。人类不仅可以从积极信号中学习,还可以从纠正负面行为中学习。

对比学习中的关键步骤是:
- 定义距离度量
- 正样本的生成/选择
- 负样本的生成/选择
通常情况下,样本被编码到向量空间中,欧几里得距离将被用来表示一对样本之间的距离。一旦我们找到生成/选择正负样本的策略,我们就可以定义一个三元组 $(x, x^+, x^-)$,其中包含一个锚定样本 $x$,一个正样本 $x^+$ 和一个负样本 $x^-$。三元组损失可以表示为:
$$ L = max(0, ||x - x^{+}||^2 - ||x - x^{-}||^2 + m) $$三元组损失被广泛用作对比学习的目标函数。
SimCSE:面向NLP的对比学习框架
SimCSE包括两个版本:无监督和监督,如下图所示。
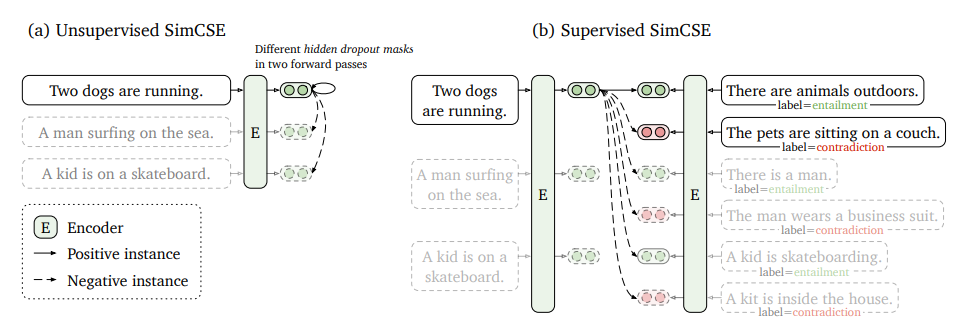
无监督SimCSE从批内负样本中预测输入句子本身,并应用不同的隐藏丢弃掩码。监督SimCSE利用NLI数据集,将蕴含(前提-假设)对作为正例,将矛盾对以及批内其他实例作为负例。
假设一组成对示例 $\mathcal{D} = {(x_i, x\_i^+)}\_{i=1}^m$,其中 $x_i$ 和 $x_i^+$ 语义相关。令 $\mathbf{h}_i$ 和 $\mathbf{h}_i^+$ 表示 $x_i$ 和 $x_i^+$ 的表示,$(x_i, x_i^+)$ 的训练目标与 $N$ 对小批量为:
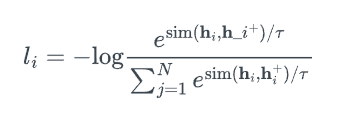
其中 $\tau$ 是温度超参数,$\textrm{sim} (\mathbf{h}_1, \mathbf{h}_2)$ 是余弦相似度。
无监督的SimCSE
无监督的SimCSE将一句话输入两次以获得两个不同的嵌入。这两个嵌入不同的原因是,模型中的dropout层会随机将输入单元设置为0,以便每次运行模型时输出不同。
在每个批次中,从相同的句子生成的两个不同嵌入将被视为正样本,而其他句子的输出将用作负样本。剩下的事情就是优化模型参数,使正样本彼此更接近,同时将负样本分离。
监督的SimCSE
在标记的数据集中,我们需要做的只是使用已有的数据创建一个三元组分支。一旦我们解决了正负样本的问题,下面的想法与无监督的SimCSE类似。
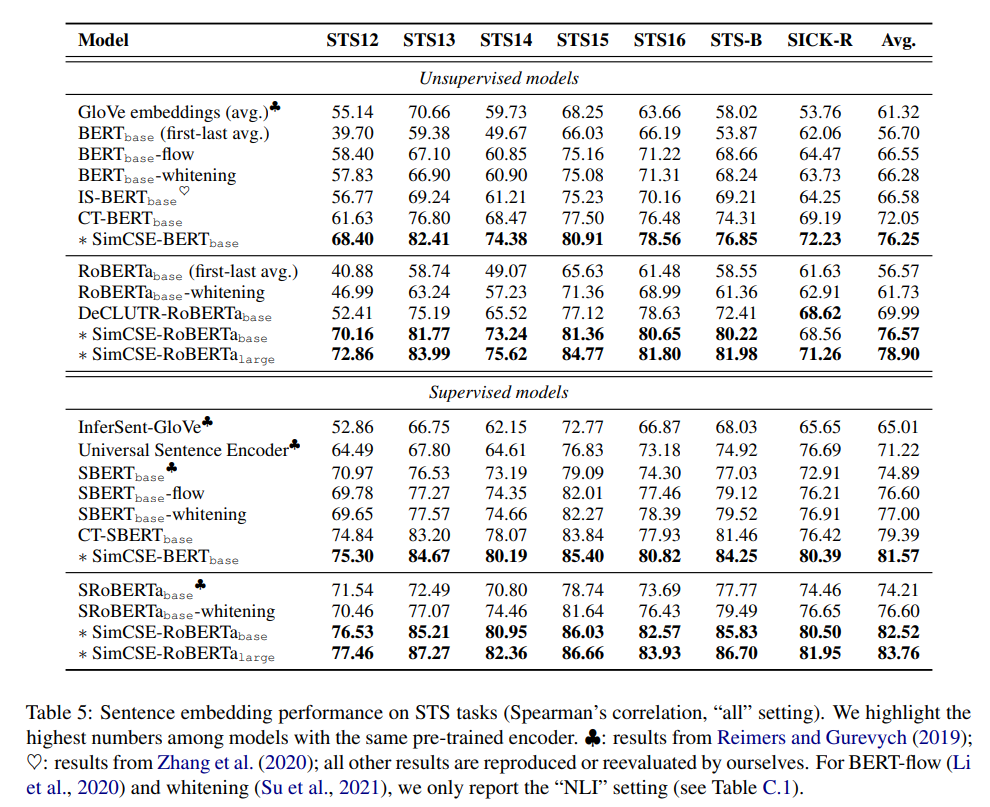
结果
提出的SimCSE极大地改进了语义文本相似性任务中的最新句子嵌入。