Transformer - Attention Is All You Need

Brief introduction to the famous paper about Transformers: Attention Is All You Need
Transformer
Paper: Attention Is All You Need
1. Background
- encoder-decoder
- self attention
- feed-forward network
- positional encoding
Dataset: WMT 2014 English-to-French translation task
Evaluation: BLEU (bilingual evaluation understudy)
- BLEU computes the modified precision metric using n-grams to measure the similarity between the candidate text and reference text. The idea is, if a word in reference is already matched, this word cannot be matched again.
- $\text{Count}_{\text{clip}} = \min (\text{count, Max\_Ref\_Count})$
 $$
\text{BLEU} = \text{BP} \times \exp(\sum_{n=1}^N \mathbf{w_n}\log P_n)
$$
$$
\text{BLEU} = \text{BP} \times \exp(\sum_{n=1}^N \mathbf{w_n}\log P_n)
$$- $\text{BP}$ (Brevity Penalty) will be 1 if the length of candidate is the same as the length of reference translation.
- $N$: n-grams
- $\mathbf{w_n}$: the weight of each modified precision
Before transformer was introduced, sequence-to-sequence models, especially LSTM, dominated the down-stream NLP tasks. Transformer introduced self-attention which made the attention mechanisms more parallelizable and more efficient. Using self-attention to replace LSTM, it achieved a better accuracy on translation tasks.
Pretraining model based on transformer: BERT (using the encoder of transformer), GPT (using the decoder of transformer), ALBERT
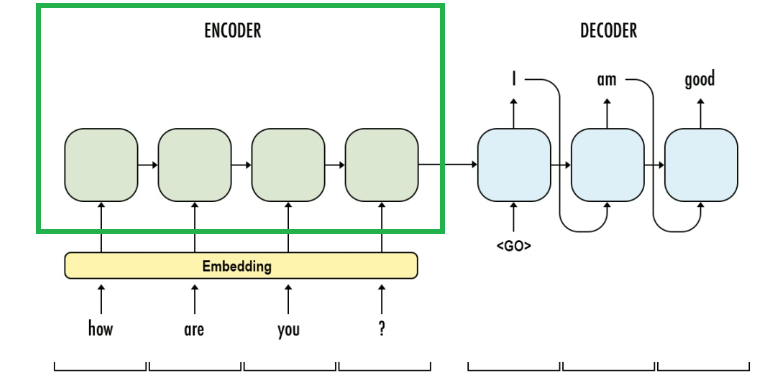
2. Seq2Seq and Attention
 $$\text{Attention}(Q,K,V) = \text{softmax}(QK^\top)V$$
$$\text{Attention}(Q,K,V) = \text{softmax}(QK^\top)V$$Details about Seq2Seq model will be updated in another blog post in the future.
Stanford 224N gives an introduction to Sequence-to-Sequence Models and Attention:
3. Transformer
3.1 Architecture

Encoder: As it is stated in the paper,
- the encoder consists of 6 identical layers
- there are two sub-layers in each layer: 1) a multi-head self-attention mechanism and 2) a simple, positional fully connected feed-forward network
- in each sub-layer, layer normalisation and residual connection are applied
Decoder:
- the decoder also consists of 6 identical layers
- there are three sub-layers in each layer: 1) a masked multi-head self-attention mechanism, 2) a simple, positional fully connected feed-forward network and 3) a multi-head attention over the output of the encoder stack
- in each sub-layer, layer normalisation and residual connection are applied
Layer Normalisation
$$LN(x_i)= \alpha\times \frac{x_i - \mu_L}{\sqrt{\sigma^2 + \epsilon}} + \beta$$
Why we use a mask in the decoder?
This modified self-attention mechanism is used to prevent positions from attending to subsequent positions.
There are two kinds of masks being applied in the transformer: sequence mask and padding mask. Padding mask is applied in all the scaled dot-product attention while sequence mask is only used in the decoder.
Mask 1: Sequence Mask
During training, in a supervised learning task, we can see the reference translation so that cheating will possibly occur in this situation. In the figure below we can see the attention matrix. Each row in the matrix represents an output and each column represent an input. Attention matrix shows the correlation between output and input. In this case, applying a lower triangular mask on the matrix can let the following output only depend on the previous output.

Mask 2: Padding Mask
We need to align the sequences since the sequence length in different batches are different. The attention mechanism should not focus on those positions. One way to deal with those meaningless positions is to assign a very negative value to those positions so that after softmax, the probability will be extremely closed to 0.
3.2 Attention
An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors.

3.2.1 Scaled Dot-Product Attention

Input (after embedding):
- $\mathbf{}$$\mathbf{x_1}$:
[batch_size, 1, embedding_dim = 512] - $\mathbf{x_2}$:
[batch_size, 1, embedding_dim = 512]
Parameters:
- $\mathbf{W}^Q: 512\times 64$
- $\mathbf{W}^K: 512\times 64$
- $\mathbf{W}^V: 512\times 64$
So, what is $Q,K,V$? In the self-attention of encoder, $Q,K,V$ come from the output of the previous encoder layer. Especially, for the first layer, they are the sum of word embedding and positional encoding. In decoder, $Q,K,V$ come from the output of the previous decoder layer. Similarly, in the first layer, they are also the sum of word embedding and positional encoding. The difference between decoder and encoder, as it is mentioned before, the decoder uses mask to hide the information in the following steps. In the encoder-decoder attention, $Q$ comes from the output of previous decoder layer while $K,V$ come from the output of the encoder so that the decoder can attend over all positions in the input squence.

$d_k$ is the dimension of keys. When $d_k$ is large, the dot-production might get huge so that the gradients of the softmax function can be extremely small (since $\exp$ will also scale the huge value in the denominator). Dividing it by the dimension can prevent this issue from happening.
Encoder example:

In the figure above, multiplying $q_1, k_1$ and $q_1, k_2$ and applying a softmax, we can get a higher probability for “thinking-thinking” than “thinking-machines”. This shows that the influence on “thinking” itself is greater than the influence on “machines”, which is certain. The following computation is shown in the figure below.

$b_1$ (or $b^1$ in this figure) represents the sum of similarity score of word $x_1$ (or $x^1$ in this figure) to all the other words in this sentence.
3.2.2 Multi-Head Attention
Just like its name, multi-head means we split $Q,K,V$ into several pieces (heads) using a linear projection and do parallel computing. The figure below shows an example of the computing using 2 heads. The “split” here does not mean we split the $Q,K,V$ matrices. It means that instead of initialising one set of $Q,K,V$ matrices, we initialise $h$ set (in the paper $h = 8$). So we will get $h$ of $Z$ at the end. However, the feed-forward network cannot accept multiple matrices as the input, so we choose to concatenate these $h$ matrices to one, and initialise a $W^O$ matrix. Multiplying the concatenated matrix $Z$ with $W^O$ gives us the output.

The shape of the matrices mentioned in the figure below (the setting in the paper):
- $X, R: m\times 512$
- $W^K,W^Q,W^V: 512\times 64$
- $Q,K,V: m \times 64$
- $Z_i: m \times 64$
- $Z: m\times 64*8 = m \times 512$
- $W^O: 512\times 512$
 $$\text{MultiHead}(Q,K,V) = \text{Concat}(\text{head}_1, \dots , \text{head}_h)W^O \\ \text{where } \text{head}_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V)$$
$$\text{MultiHead}(Q,K,V) = \text{Concat}(\text{head}_1, \dots , \text{head}_h)W^O \\ \text{where } \text{head}_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V)$$The projections are parameter matrices $W_i^Q \in R^{d_\text{model} \times d_k}, W_i^K \in R^{d_\text{model} \times d_k}, W_i^V \in R^{d_\text{model} \times d_v},$ and $W_i^O \in R^{hd_v \times d_\text{model}}$.
3.2.3 Short Summary of Attention
| Queries | Keys | Values | |
|---|---|---|---|
| encoder-encoder | encoder-inputs | encoder-inputs | encoder-inputs |
| encoder-decoder | decoder-inputs | encoder-inputs | encoder-inputs |
| decoder-decoder | decoder-inputs | decoder-inputs | decoder-inputs |
We can see from the table that in encoder-decoder attention, the queries are different from keys and values while they are the same in encoder-encoder attention and decoder-decoder attention. One more thing we need to care about is that we are using several encoder / decoder layers, we have to make sure that the outputs are in the same size as the inputs. The size is always be $(\text{batch_size} \times \text{sequence_length} \times \text{embedding_dim})$.
3.3 Feed-Forward Network
The encoder and decoder also contain s a fully connected feed-forward network. The feed-forward network consists of two layers: 1) linear activation function, 2) ReLU. $x$ is the output of self-attention and $W_1, W_2, b_1, b_2$ are the parameters to learn.
$$ \text{FFN}(x) = \max (0, xW_1+b_1)W_2 +b_2 $$3.4 Positional Encoding
$$ PE_{(pos,2i)} = \sin (\frac{pos}{10000^{2i/d_\text{model}}}) $$$$ PE_{(pos,2i+1)} = \cos (\frac{pos}{10000^{2i/d_\text{model}}}) $$Since our model contains no recurrence and no convolution, in order for the model to make use of the order of the sequence, we must inject some information about the relative or absolute position of the tokens in the sequence.
- $i$: dimension
- $pos$: position
- $d_\text{model}$: the embedding dimension
For example, if we have a token where $pos =3$ and $d_\text{model} = 512$, the positional encoding will be:
$$ (\sin \frac{3}{10000^{0/256}}, \cos \frac{3}{10000^{1/256}}, \sin \frac{3}{10000^{2/256}}, \cos \frac{3}{10000^{3/256}}, \dots) $$That means for even positions, we use $\sin$ for encoding while using $\cos$ for odd positions. Positional encoding uses the absolute position encoder. However, the relative position also contains significant information. That’s why we use trigonometric functions.
$$ \sin(\alpha+\beta) = \sin \alpha \cos \beta + \cos \alpha \sin \beta \\ \cos(\alpha + \beta) = \cos \alpha \cos \beta - \sin \alpha \sin \beta $$Therefore, for any offset $k$ between a pair of tokens, $PE(pos + k)$ can be represented by $PE(pos)$ and $PE(k)$, which means we can represent the relative positions.
4. Experimental Setup and Result
The experimental setup including the hardware information and hyperparameters can be viewed in the original paper. They evaluated the model on English-to-German task and English-to-French task and both achieved higher accuracy than the SOTA models at that time.