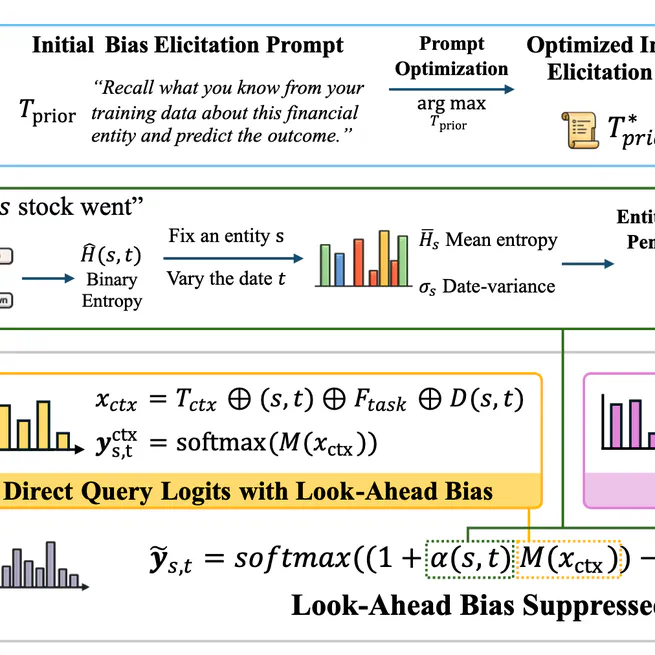
Summoning the Oracle to Slay It: Mitigating Look-Ahead Bias in Financial Backtesting with Large Language Models
Citation @misc{li2026summoningoracleslayit, title={Summoning the Oracle to Slay It: Mitigating Look-Ahead Bias in Financial Backtesting with Large Language Models}, author={Weixian Waylon Li and Mengyu Wang and Tiejun Ma}, year={2026}, eprint={2605.24564}, archivePrefix={arXiv}, primaryClass={cs.AI}, url={https://arxiv.org/abs/2605.24564}, }
5月 26, 2026
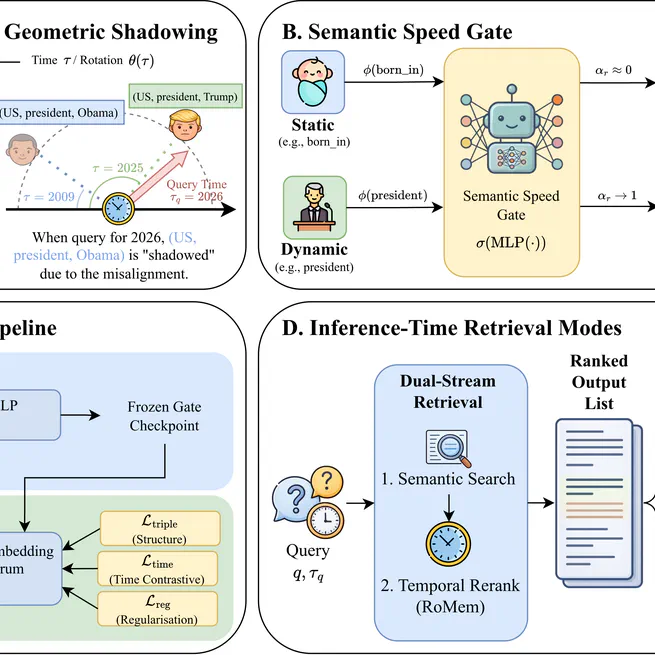
Time is Not a Label: Continuous Phase Rotation for Temporal Knowledge Graphs and Agentic Memory
Citation @misc{li2026timelabelcontinuousphase, title={Time is Not a Label: Continuous Phase Rotation for Temporal Knowledge Graphs and Agentic Memory}, author={Weixian Waylon Li and Jiaxin Zhang and Xianan Jim Yang and Tiejun Ma and Yiwen Guo}, year={2026}, eprint={2604.11544}, archivePrefix={arXiv}, primaryClass={cs.CL}, url={https://arxiv.org/abs/2604.11544}, }
4月 14, 2026
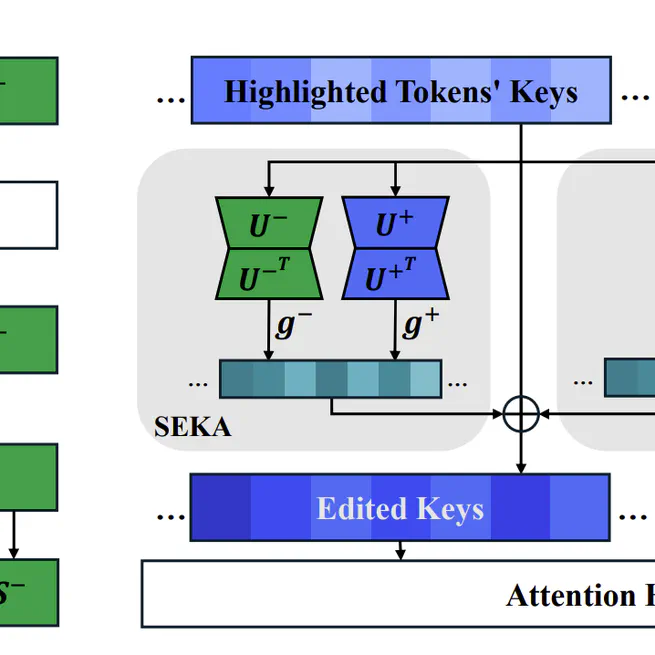
Spectral Attention Steering for Prompt Highlighting
Citation @inproceedings{ li-2026spectral, title={Spectral Attention Steering for Prompt Highlighting}, author={Li, Weixian Waylon and Niu, Yuchen and Yang, Yongxin and Li, Keshuang and Ma, Tiejun and Cohen, Shay B.}, booktitle={The Fourteenth International Conference on Learning Representations}, year={2026}, url={https://openreview.net/forum?id=XfLvGIFmAN} }
1月 27, 2026
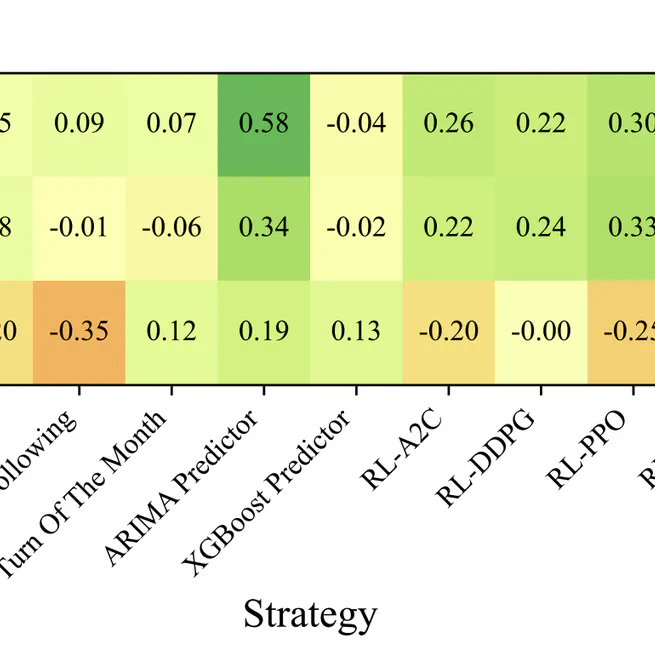
Can LLM-based Financial Investing Strategies Outperform the Market in Long Run?
Citation @inproceedings{10.1145/3770854.3785702, author = {Li, Weixian Waylon and Kim, Hyeonjun and Cucuringu, Mihai and Ma, Tiejun}, title = {Can LLM-based Financial Investing Strategies Outperform the Market in Long Run?}, year = {2026}, isbn = {9798400722585}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, url = {https://doi.org/10.1145/3770854.3785702}, doi = {10.1145/3770854.3785702}, abstract = {Large Language Models (LLMs) have recently been leveraged for asset pricing and stock trading applications, enabling AI agents to generate investment decisions from unstructured financial data. However, most evaluations of LLM timing-based investing strategies are conducted on narrow timeframes and limited stock universes, overstating effectiveness due to survivorship and data-snooping biases. We critically assess their generalizability and robustness by proposing FINSABER, a backtesting framework evaluating timing-based strategies across longer periods and a larger universe of symbols. Systematic backtests over two decades and 100+ symbols reveal that previously reported LLM advantages deteriorate significantly under broader cross-section and over a longer-term evaluation. Our market regime analysis further demonstrates that LLM strategies are overly conservative in bull markets, underperforming passive benchmarks, and overly aggressive in bear markets, incurring heavy losses. These findings highlight the need to develop LLM strategies that are able to prioritise trend detection and regime-aware risk controls over mere scaling of framework complexity.}, booktitle = {Proceedings of the 32nd ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.1}, pages = {2711–2722}, numpages = {12}, keywords = {automated trading, llm investors, backtest, benchmark}, location = {Republic of Korea}, series = {KDD '26} }
11月 24, 2025

BERT Is Not The Count: Learning to Match Mathematical Statements with Proofs
Citation @inproceedings{li-etal-2023-bert, title = "{BERT} Is Not The Count: Learning to Match Mathematical Statements with Proofs", author = "Li, Weixian Waylon and Ziser, Yftah and Coavoux, Maximin and Cohen, Shay B.", editor = "Vlachos, Andreas and Augenstein, Isabelle", booktitle = "Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics", month = may, year = "2023", address = "Dubrovnik, Croatia", publisher = "Association for Computational Linguistics", url = "https://aclanthology.org/2023.eacl-main.260", doi = "10.18653/v1/2023.eacl-main.260", pages = "3581--3593", abstract = "We introduce a task consisting in matching a proof to a given mathematical statement. The task fits well within current research on Mathematical Information Retrieval and, more generally, mathematical article analysis (Mathematical Sciences, 2014). We present a dataset for the task (the MATcH dataset) consisting of over 180k statement-proof pairs extracted from modern mathematical research articles. We find this dataset highly representative of our task, as it consists of relatively new findings useful to mathematicians. We propose a bilinear similarity model and two decoding methods to match statements to proofs effectively. While the first decoding method matches a proof to a statement without being aware of other statements or proofs, the second method treats the task as a global matching problem. Through a symbol replacement procedure, we analyze the {``}insights{''} that pre-trained language models have in such mathematical article analysis and show that while these models perform well on this task with the best performing mean reciprocal rank of 73.7, they follow a relatively shallow symbolic analysis and matching to achieve that performance.", }
5月 1, 2023